前述
- 在
8.x版本中,ES出了一个新的Elasticsearch Java API Client,点击查看 (opens new window),如果你要在Springboot高版本中使用,可以直接使用该API。 ES7.X版本的JAVA-API请查看🔎- 以下示例,首先需要将
elasticsearch.yml中的有关ssl的配置全部改为false,本地测试就不搞HTTPS那么麻烦了 - 示例代码已经上传到gitee (opens new window)
项目配置
依赖引入
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.3.3</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
<!--It may happen that after setting up the dependencies, your application fails with ClassNotFoundException: jakarta.json.spi.JsonProvider.-->
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
注意:elasticsearch 的两个依赖要和 elasticsearch 服务器版本一致。
客户端对象
@Test
void ElasticsearchClientBuild() throws IOException {
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("127.0.0.1", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient elasticsearchClient = new ElasticsearchClient(transport);
System.out.println("elasticsearchClient = " + elasticsearchClient);
restClient.close();
}
结果输出
elasticsearchClient = co.elastic.clients.elasticsearch.ElasticsearchClient@6e4f263e
配置获取客户端对象
- yml配置
elasticsearch:
host: 127.0.0.1
port: 9200
http: http
- 配置 ElasticClient
/**
* @version 1.0.0
* @className: ElasticClient
* @description: 配置获取ES客户端对象
* @author: smartzeng
* @create: 2022/8/8 9:58
*/
@Component
public class ElasticClient {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private Integer port;
@Value("${elasticsearch.http}")
private String http;
/**
* 获取elasticsearch客户端
*
* @return {@link ElasticsearchClient}
*/
@Bean
public ElasticsearchClient getElasticsearchClient() {
RestClient restClient = RestClient.builder(
new HttpHost(host, port,http)).build();
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}
索引操作
创建索引
@SpringBootTest
@Slf4j
public class IndexTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 创建索引
*
* @throws IOException ioexception
*/
@Test
void createIndex() throws IOException {
CreateIndexResponse response = elasticsearchClient.indices().create(c -> c.index("products"));
//响应状态
boolean acknowledged = response.acknowledged();
boolean shardsAcknowledged = response.shardsAcknowledged();
String index = response.index();
log.info("创建索引状态:{}",acknowledged);
log.info("已确认的分片:{}",shardsAcknowledged);
log.info("索引名称:{}",index);
}
}
结果
[main] c.e.e.ElasticsearchApplicationTests : elasticsearchClient:co.elastic.clients.elasticsearch.ElasticsearchClient@6f911326
[main] c.e.e.ElasticsearchApplicationTests : 创建索引状态:true
[main] c.e.e.ElasticsearchApplicationTests : 已确认的分片:true
[main] c.e.e.ElasticsearchApplicationTests : 索引名称:products
查看索引
/**
* @version 1.0.0
* @className: IndexTest
* @description: 索引测试
* @author: smartzeng
* @create: 2022/8/8 10:03
*/
@SpringBootTest
@Slf4j
public class IndexTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 获取索引
*/
@Test
void getIndex() throws IOException
{
// 查看指定索引
GetIndexResponse getIndexResponse = elasticsearchClient.indices().get(s -> s.index("products"));
Map<String, IndexState> result = getIndexResponse.result();
result.forEach((k, v) -> log.info("key = {},value = {}",k ,v));
// 查看全部索引
IndicesResponse indicesResponse = elasticsearchClient.cat().indices();
// 返回对象具体查看 co.elastic.clients.elasticsearch.cat.indices.IndicesRecord
indicesResponse.valueBody().forEach(
info -> log.info("health:{}\n status:{} \n uuid:{} \n ",info.health(),info.status(),info.uuid())
);
}
}
结果
key = products,
value = IndexState:
{
"aliases":{
},
"mappings":{
},
"settings":{
"index":{
"number_of_shards":"1",
"number_of_replicas":"1",
"routing":{
"allocation":{
"include":{
"_tier_preference":"data_content"
}
}
},
"provided_name":"products",
"creation_date":"1659923692276",
"uuid":"WN0uQLLvQ1SdFsWE2bhlgw",
"version":{
"created":"8030399"
}
}
}
}
删除索引
/**
* @version 1.0.0
* @className: IndexTest
* @description: 索引测试
* @author: smartzeng
* @create: 2022/8/8 10:03
*/
@SpringBootTest
@Slf4j
public class IndexTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 删除索引
*
* @throws IOException ioexception
*/
@Test
void deleteIndex() throws IOException {
DeleteIndexResponse deleteIndexResponse = elasticsearchClient.indices().delete(s -> s.index("products"));
log.info("删除索引操作结果:{}",deleteIndexResponse.acknowledged());
}
}
结果
[main] com.example.elasticsearch.IndexTest : 删除索引操作结果:true
总结
关于索引的请求,用到 elasticsearchClient.indices().xxx(s -> s.index("索引名")) ,其中 xxx 代表增删查
文章操作
新增实体类:User
public class User
{
private String id;
private String name;
private Integer age;
private String sex;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public User()
{
}
public User(String id, String name, Integer age, String sex) {
this.id = id;
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "User{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
'}';
}
}
新增文档
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 添加一个文档
* @see: https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.3/indexing.html#indexing
* @throws IOException ioexception
*/
@Test
void addOneDocument () throws IOException
{
// 1、using the fluent DSL
User user = new User("1","王五",28,"男");
IndexResponse indexResponse = elasticsearchClient.index(s ->
// 索引
s.index("users")
// ID
.id(user.getId())
// 文档
.document(user)
);
log.info("result:{}",indexResponse.result().jsonValue());
// 2、You can also assign objects created with the DSL to variables. Java API Client classes have a static of() method for this, that creates an object with the DSL syntax.
IndexRequest<User> request = IndexRequest.of(i -> i
.index("users")
.id(user.getId())
.document(user));
IndexResponse response = elasticsearchClient.index(request);
log.info("Indexed with version " + response.version());
// 3、Using classic builders
IndexRequest.Builder<User> indexReqBuilder = new IndexRequest.Builder<>();
indexReqBuilder.index("users");
indexReqBuilder.id(user.getId());
indexReqBuilder.document(user);
IndexResponse responseTwo = elasticsearchClient.index(indexReqBuilder.build());
log.info("Indexed with version " + responseTwo.version());
}
}
结果
[main] com.example.elasticsearch.DocTest : user.id:e051445c-ae8c-47ef-ab18-97b34025d49a
[main] com.example.elasticsearch.DocTest : result:created
查询文档
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 获取文档
* https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.3/reading.html#reading
* @throws IOException ioexception
*/
@Test
void getDocument () throws IOException
{
// co.elastic.clients.elasticsearch.core.get.GetResult<TDocument>
GetResponse<User> getResponse = elasticsearchClient.get(s -> s.index("users").id("e051445c-ae8c-47ef-ab18-97b34025d49a"),User.class);
log.info("getResponse:{}",getResponse.source());
// Reading a domain object
if (getResponse.found())
{
User user = getResponse.source();
assert user != null;
log.info("user name={}",user.getName());
}
// Reading raw JSON
// if (getResponse.found())
// {
// ObjectNode json = getResponse.source();
// String name = json.get("name").asText();
// log.info("Product name " + name);
// }
// 判断文档是否存在
BooleanResponse booleanResponse = elasticsearchClient.exists(s -> s.index("users").id("e051445c-ae8c-47ef-ab18-97b34025d49a"));
log.info("判断Document是否存在:{}",booleanResponse.value());
}
}
结果
getResponse:User{id='e051445c-ae8c-47ef-ab18-97b34025d49a', name='王五', age=28, sex='男'}
更新文档
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 更新文档
*
* @throws IOException ioexception
*/
@Test
void updateDocument () throws IOException
{
// 构建需要修改的内容,这里使用了Map
Map<String, Object> map = new HashMap<>();
map.put("name", "liuyife");
// 构建修改文档的请求
UpdateResponse<Test> response = elasticsearchClient.update(e -> e
.index("users")
.id("33")
.doc(map),
Test.class
);
// 打印请求结果
log.info(String.valueOf(response.result()));
}
}
结果
[main] com.example.elasticsearch.DocTest : Updated
删除文档
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 删除文档
*
* @throws IOException ioexception
*/
@Test
void deleteDocument () throws IOException
{
DeleteResponse deleteResponse = elasticsearchClient.delete(s -> s.index("users").id("e051445c-ae8c-47ef-ab18-97b34025d49a"));
log.info("删除文档操作结果:{}",deleteResponse.result());
}
}
结果
[main] com.example.elasticsearch.DocTest: 删除文档操作结果:Deleted
批量新增
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 批量添加文档
*
* @throws IOException ioexception
*/
@Test
void batchAddDocument () throws IOException
{
// 1、use BulkOperation
List<User> users = new ArrayList<>();
users.add(new User("1","赵四",20,"男"));
users.add(new User("2","阿旺",25,"男"));
users.add(new User("3","刘菲",22,"女"));
users.add(new User("4","冬梅",20,"女"));
List<BulkOperation> bulkOperations = new ArrayList<>();
users.forEach(u ->
bulkOperations.add(BulkOperation.of(b ->
b.index(
c ->
c.id(u.getId()).document(u)
)))
);
BulkResponse bulkResponse = elasticsearchClient.bulk(s -> s.index("users").operations(bulkOperations));
bulkResponse.items().forEach(i ->
log.info("i = {}" , i.result()));
log.error("bulkResponse.errors() = {}" , bulkResponse.errors());
// 2、use BulkRequest
BulkRequest.Builder br = new BulkRequest.Builder();
for (User user : users) {
br.operations(op -> op
.index(idx -> idx
.index("users")
.id(user.getId())
.document(user)));
}
BulkResponse result = elasticsearchClient.bulk(br.build());
// Log errors, if any
if (result.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item: result.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
}
}
结果
[main] com.example.elasticsearch.DocTest : i = created
[main] com.example.elasticsearch.DocTest : i = created
[main] com.example.elasticsearch.DocTest : i = created
[main] com.example.elasticsearch.DocTest : i = created
[main] com.example.elasticsearch.DocTest : bulkResponse.errors() = false
批量删除
/**
* @version 1.0.0
* @className: DocTest
* @description: 文档操作测试
* @author: smartzeng
* @create: 2022/8/8 10:19
*/
@SpringBootTest
@Slf4j
public class DocTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 批量删除文档
*
* @throws IOException ioexception
*/
@Test
void batchDeleteDocument () throws IOException
{
// 1、use BulkOperation
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
List<BulkOperation> bulkOperations = new ArrayList<>();
list.forEach(a ->
bulkOperations.add(BulkOperation.of(b ->
b.delete(c -> c.id(a))
))
);
BulkResponse bulkResponse = elasticsearchClient.bulk(a -> a.index("users").operations(bulkOperations));
bulkResponse.items().forEach(a ->
log.info("result = {}" , a.result()));
log.error("bulkResponse.errors() = {}" , bulkResponse.errors());
// 2、use BulkRequest
BulkRequest.Builder br = new BulkRequest.Builder();
for (String s : list) {
br.operations(op -> op
.delete(c -> c.id(s)));
}
BulkResponse bulkResponseTwo = elasticsearchClient.bulk(br.build());
bulkResponseTwo.items().forEach(a ->
log.info("result = {}" , a.result()));
log.error("bulkResponse.errors() = {}" , bulkResponseTwo.errors());
}
}
结果
[main] com.example.elasticsearch.DocTest : result = deleted
[main] com.example.elasticsearch.DocTest : result = deleted
[main] com.example.elasticsearch.DocTest : result = deleted
[main] com.example.elasticsearch.DocTest : result = deleted
[main] com.example.elasticsearch.DocTest : bulkResponse.errors() = false
高级查询
查询准备
- 通过批量添加文档准备几条数据先
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 批量添加准备数据
*
* @throws IOException ioexception
*/
@Test
void batchAddDocument () throws IOException
{
List<User> users = new ArrayList<>();
users.add(new User("11","zhaosi",20,"男"));
users.add(new User("22","awang",25,"男"));
users.add(new User("33","liuyifei",22,"女"));
users.add(new User("44","dongmei",20,"女"));
users.add(new User("55","zhangya",30,"女"));
users.add(new User("66","liuyihu",32,"男"));
BulkRequest.Builder br = new BulkRequest.Builder();
for (User user : users) {
br.operations(op -> op
.index(idx -> idx
.index("users")
.id(user.getId())
.document(user)));
}
BulkResponse result = elasticsearchClient.bulk(br.build());
// Log errors, if any
if (result.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item: result.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
}
}
简单的搜索查询
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 条件查询方式1
*
* @throws IOException ioexception
*/
@Test
void searchOne() throws IOException {
String searchText = "liuyihu";
SearchResponse<User> response = elasticsearchClient.search(s -> s
// 我们要搜索的索引的名称
.index("users")
// 搜索请求的查询部分(搜索请求也可以有其他组件,如聚合)
.query(q -> q
// 在众多可用的查询变体中选择一个。我们在这里选择匹配查询(全文搜索)
.match(t -> t
// name配置匹配查询:我们在字段中搜索一个词
.field("name")
.query(searchText)
)
),
// 匹配文档的目标类
User.class
);
TotalHits total = response.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
List<Hit<User>> hits = response.hits().hits();
for (Hit<User> hit: hits) {
User user = hit.source();
assert user != null;
log.info("Found userId " + user.getId() + ", name " + user.getName());
}
}
}
嵌套搜索查询
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 嵌套搜索查询
*/
@Test
void searchTwo() throws IOException {
String searchText = "liuyihu";
int maxAge = 30;
// byName、byMaxAge:分别为各个条件创建查询
Query byName = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)
//MatchQuery是一个查询变体,我们必须将其转换为 Query 联合类型
._toQuery();
Query byMaxAge = RangeQuery.of(m -> m
.field("age")
// Elasticsearch 范围查询接受大范围的值类型。我们在这里创建最高价格的 JSON 表示。
.gte(JsonData.of(maxAge))
)._toQuery();
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
.bool(b -> b
// 搜索查询是结合了文本搜索和最高价格查询的布尔查询
.must(byName)
// .should(byMaxAge)
.must(byMaxAge)
)
),
User.class
);
List<Hit<User>> hits = response.hits().hits();
for (Hit<User> hit: hits) {
User user = hit.source();
assert user != null;
log.info("Found userId " + user.getId() + ", name " + user.getName());
}
}
}
模板化搜索
- 模板化搜索是存储的搜索,可以使用不同的变量运行它。搜索模板让您无需修改应用程序代码即可更改搜索。
- 在运行模板搜索之前,首先必须创建模板。这是一个返回搜索请求正文的存储脚本,通常定义为 Mustache 模板
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 模板化搜索
* 模板化搜索是存储的搜索,可以使用不同的变量运行它。搜索模板让您无需修改应用程序代码即可更改搜索。
* 在运行模板搜索之前,首先必须创建模板。这是一个返回搜索请求正文的存储脚本,通常定义为 Mustache 模板
*/
@Test
void templatedSearch() throws IOException {
// 事先创建搜索模板
elasticsearchClient.putScript(r -> r
// 要创建的模板脚本的标识符
.id("query-script")
.script(s -> s
.lang("mustache")
.source("{\"query\":{\"match\":{\"{{field}}\":\"{{value}}\"}}}")
));
// 开始使用模板搜索
String field = "name";
String value = "liuyifei";
SearchTemplateResponse<User> response = elasticsearchClient.searchTemplate(r -> r
.index("users")
// 要使用的模板脚本的标识符
.id("query-script")
// 模板参数值
.params("field", JsonData.of(field))
.params("value", JsonData.of(value)),
User.class
);
List<Hit<User>> hits = response.hits().hits();
for (Hit<User> hit: hits) {
User user = hit.source();
assert user != null;
log.info("Found userId " + user.getId() + ", name " + user.getName());
}
}
}
分页&排序查询
- 根据条件搜索的分页&排序
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 分页+排序条件搜索
*
* @throws IOException ioexception
*/
@Test
void paginationSearch() throws IOException
{
int maxAge = 20;
Query byMaxAge = RangeQuery.of(m -> m
.field("age")
.gte(JsonData.of(maxAge))
)._toQuery();
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
.bool(b -> b
.must(byMaxAge)
)
)
//分页查询,从第0页开始查询4个document
.from(0)
.size(4)
//按age降序排序
.sort(f -> f.field(o -> o.field("age")
.order(SortOrder.Desc))),
User.class
);
List<Hit<User>> hits = response.hits().hits();
for (Hit<User> hit: hits) {
User user = hit.source();
assert user != null;
log.info("Found userId " + user.getId() + ", name " + user.getName());
}
}
}
结果
[
{
"id":"66",
"name":"liuyihu",
"age":32,
"sex":"男"
},
{
"id":"55",
"name":"zhangya",
"age":30,
"sex":"女"
},
{
"id":"c49fa7a2-f8dc-45a4-8ea8-340f10a6162e",
"name":"zhangSan",
"age":28,
"sex":"男"
},
{
"id":"1",
"name":"王五",
"age":28,
"sex":"男"
}
]
- 查询所有并进行分页&排序
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 分页+排序条件搜索
*
* @throws IOException ioexception
*/
@Test
void paginationSearch() throws IOException
{
int maxAge = 20;
Query byMaxAge = RangeQuery.of(m -> m
.field("age")
.gte(JsonData.of(maxAge))
)._toQuery();
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
.matchAll( m -> m)
)
.from(0)
.size(6)
.sort(f -> f.field(o -> o.field("age")
.order(SortOrder.Desc))),
User.class
);
List<Hit<User>> hits = response.hits().hits();
for (Hit<User> hit: hits) {
User user = hit.source();
assert user != null;
log.info("Found userId " + user.getId() + ", name " + user.getName());
}
}
}
结果
[
{
"id":"66",
"name":"liuyihu",
"age":32,
"sex":"男"
},
{
"id":"55",
"name":"zhangya",
"age":30,
"sex":"女"
},
{
"id":"c49fa7a2-f8dc-45a4-8ea8-340f10a6162e",
"name":"zhangSan",
"age":28,
"sex":"男"
},
{
"id":"1",
"name":"王五",
"age":28,
"sex":"男"
},
{
"id":"22",
"name":"awang",
"age":25,
"sex":"男"
},
{
"id":"33",
"name":"liuyifei",
"age":22,
"sex":"女"
},
{
"id":"11",
"name":"zhaosi",
"age":20,
"sex":"男"
},
{
"id":"44",
"name":"dongmei",
"age":20,
"sex":"女"
}
]
过滤字段
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 过滤字段
*
* @throws IOException ioexception
*/
@Test
void filterFieldSearch() throws IOException
{
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
.matchAll( m -> m)
)
.sort(f -> f
.field(o -> o
.field("age")
.order(SortOrder.Desc)
)
)
.source(source -> source
.filter(f -> f
.includes("name","id")
.excludes(""))),
User.class
);
List<Hit<User>> hits = response.hits().hits();
List<User> userList = new ArrayList<>(hits.size());
for (Hit<User> hit: hits) {
User user = hit.source();
userList.add(user);
}
log.info("过滤字段后:{}",JSONUtil.toJsonStr(userList));
}
}
结果
[
{
"id":"66",
"name":"liuyihu"
},
{
"id":"55",
"name":"zhangya"
},
{
"id":"c49fa7a2-f8dc-45a4-8ea8-340f10a6162e",
"name":"zhangSan"
},
{
"id":"1",
"name":"王五"
},
{
"id":"22",
"name":"awang"
},
{
"id":"33",
"name":"liuyifei"
},
{
"id":"11",
"name":"zhaosi"
},
{
"id":"44",
"name":"dongmei"
}
]
模糊查询
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 模糊查询
*
* @throws IOException ioexception
*/
@Test
void fuzzyQuerySearch() throws IOException
{
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
// 模糊查询
.fuzzy(f -> f
// 需要判断的字段名称
.field("name")
// 需要模糊查询的关键词
// 目前文档中没有liuyi这个用户名
.value("liuyi")
// fuzziness代表可以与关键词有误差的字数,可选值为0、1、2这三项
.fuzziness("2")
)
)
.source(source -> source
.filter(f -> f
.includes("name","id")
.excludes(""))),
User.class
);
List<Hit<User>> hits = response.hits().hits();
List<User> userList = new ArrayList<>(hits.size());
for (Hit<User> hit: hits) {
User user = hit.source();
userList.add(user);
}
log.info("过滤字段后:{}",JSONUtil.toJsonStr(userList));
}
}
结果
[
{
"id":"66",
"name":"liuyihu"
}
]
高亮查询
/**
* @version 1.0.0
* @className: SearchTest
* @description: 查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class SearchTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 高亮查询
*
* @throws IOException ioexception
*/
@Test
void highlightQueryQuery() throws IOException
{
SearchResponse<User> response = elasticsearchClient.search(s -> s
.index("users")
.query(q -> q
.term(t -> t
.field("name")
.value("zhaosi"))
)
.highlight(h -> h
.fields("name", f -> f
.preTags("<font color='red'>")
.postTags("</font>")))
.source(source -> source
.filter(f -> f
.includes("name","id")
.excludes(""))),
User.class
);
List<Hit<User>> hits = response.hits().hits();
List<User> userList = new ArrayList<>(hits.size());
for (Hit<User> hit: hits) {
User user = hit.source();
userList.add(user);
for(Map.Entry<String, List<String>> entry : hit.highlight().entrySet())
{
System.out.println("Key = " + entry.getKey());
entry.getValue().forEach(System.out::println);
}
}
log.info("模糊查询结果:{}",JSONUtil.toJsonStr(userList));
}
}
结果
Key = name
<font color='red'>zhaosi</font>
聚合查询
最大值
/**
* @version 1.0.0
* @className: SearchTest
* @description: 聚合查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class PartyTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 获取最大年龄用户
*/
@Test
void getMaxAgeUserTest() throws IOException {
SearchResponse<Void> response = elasticsearchClient.search(b -> b
.index("users")
.size(0)
.aggregations("maxAge", a -> a
.max(MaxAggregation.of(s -> s
.field("age"))
)
),
Void.class
);
MaxAggregate maxAge = response.aggregations()
.get("maxAge")
.max();
log.info("maxAge.value:{}",maxAge.value());
}
}
分组统计
LongTermsAggregate类型
/**
* @version 1.0.0
* @className: SearchTest
* @description: 聚合查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class PartyTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 年龄分组
*
* @throws IOException ioexception
*/
@Test
void groupingTest() throws IOException {
SearchResponse<Void> response = elasticsearchClient.search(b -> b
.index("users")
.size(0)
.aggregations("groupName", a -> a
.terms(TermsAggregation.of(s -> s
.field("age")))
),
Void.class
);
LongTermsAggregate longTermsAggregate = response.aggregations()
.get("groupName")
.lterms();
log.info("multiTermsAggregate:{}",longTermsAggregate.buckets());
}
}
结果
[
{
"doc_count":2,
"key":20
},
{
"doc_count":2,
"key":28
},
{
"doc_count":1,
"key":22
},
{
"doc_count":1,
"key":25
},
{
"doc_count":1,
"key":30
},
{
"doc_count":1,
"key":32
}
]
StringTermsAggregate类型
/**
* @version 1.0.0
* @className: SearchTest
* @description: 聚合查询测试
* @author: smartzeng
* @create: 2022/8/8 11:04
*/
@SpringBootTest
@Slf4j
public class PartyTest
{
@Autowired
private ElasticsearchClient elasticsearchClient;
/**
* 性别分组
*
* @throws IOException ioexception
*/
@Test
void groupBySexTest() throws IOException {
SearchResponse<Void> response = elasticsearchClient.search(b -> b
.index("users")
.size(0)
.aggregations("groupSex", a -> a
.terms(TermsAggregation.of(s -> s
// ⚠️特别注意这一块,我们加上了.keyword,下面会说明
.field("sex.keyword")))
),
Void.class
);
StringTermsAggregate stringTermsAggregate = response.aggregations()
.get("groupSex")
.sterms();
log.info("stringTermsAggregate:{}",stringTermsAggregate.buckets());
}
}
结果
[
{
"doc_count":5,
"key":"男"
},
{
"doc_count":3,
"key":"女"
}
]
问题
- 在
性别分组代码中,有一块地方我们要注意下。我们根据性别分组,按理来说,field直接写sex就行,但是我们发现,如果不加.keyword,运行测试用例会报错,错误如下: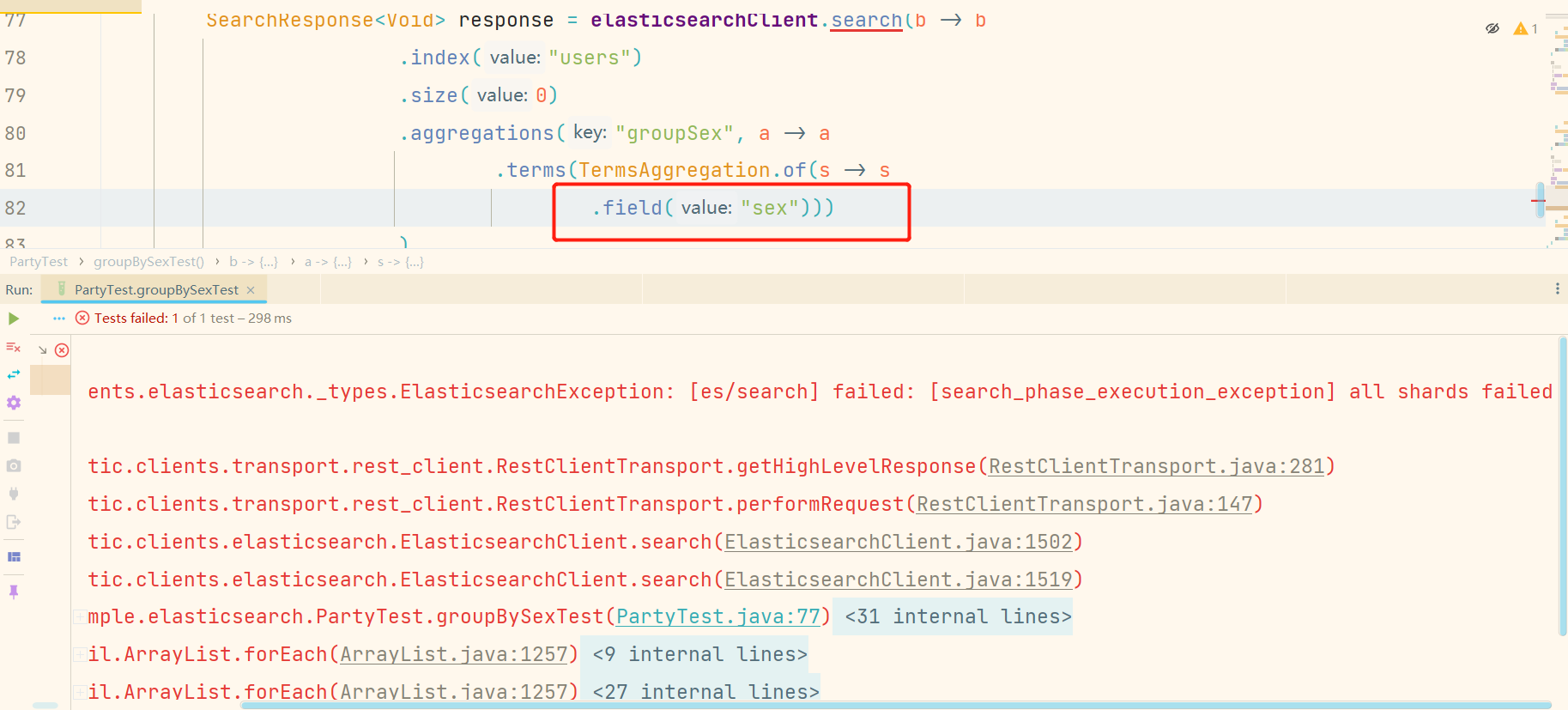
原因分析:
这个错误的原因是因为我的分组聚合查询的字符串sex类型是text类型。当使用到 term 查询的时候,由于是精准匹配,所以查询的关键字在es上的类型,必须是keyword而不能是text。所以想要分组查询,指定根据分组字段的keyword属性就可以了。